




Az első kísérlet a Magyar Közlönyön
Használható-e vagy még inkább: használható-e már a mesterséges intelligencia (MI) jogkeresésre? Most induló posztsorozatunkban különböző modellek összevetésével vizsgáljuk meg, hogyan boldogul jelenleg a technológia, ha jogszabályokat – különösen magyar jogszabályokat – kell felkutatnia. Elsőként a Magyar Közlöny MI-feldolgozhatóságát vesszük górcső alá. Mint látható lesz, hamar falakba is ütközünk. Küldetésünkhöz illően azonban természetesen nem hagyjuk az olvasót megoldási javaslatok nélkül.
A jogi tájékozódás új korszaka?
A mesterséges intelligencia térhódítását manapság már nem kell magyarázni, kis túlzással lassan a csapból is mesterséges intelligencia folyik. E blog keretei közt is számos aspektussal foglalkoztunk már: a kompetenciaszintektől a fejlődést hátráltató jogi tényezőkön, etikai és a szerzői jogi kérdéseken át egészen az MI-függésig vagy a gyermekek áldozattá válásáig. Sőt, szóltunk a közoktatási vagy egyetemi felhasználásról, az egészségügyi alkalmazásról, láthattuk, hogy támogatja az ajánlattevőket közbeszerzésben vagy a digitális kultúrához hozzáférést az abban korlátozottaknak. Itt az ideje azt is a gyakorlatban megvizsgálni, segíthet-e, illetve hogyan segíthet az MI jogszabályok felkutatásában, összefoglalásában.
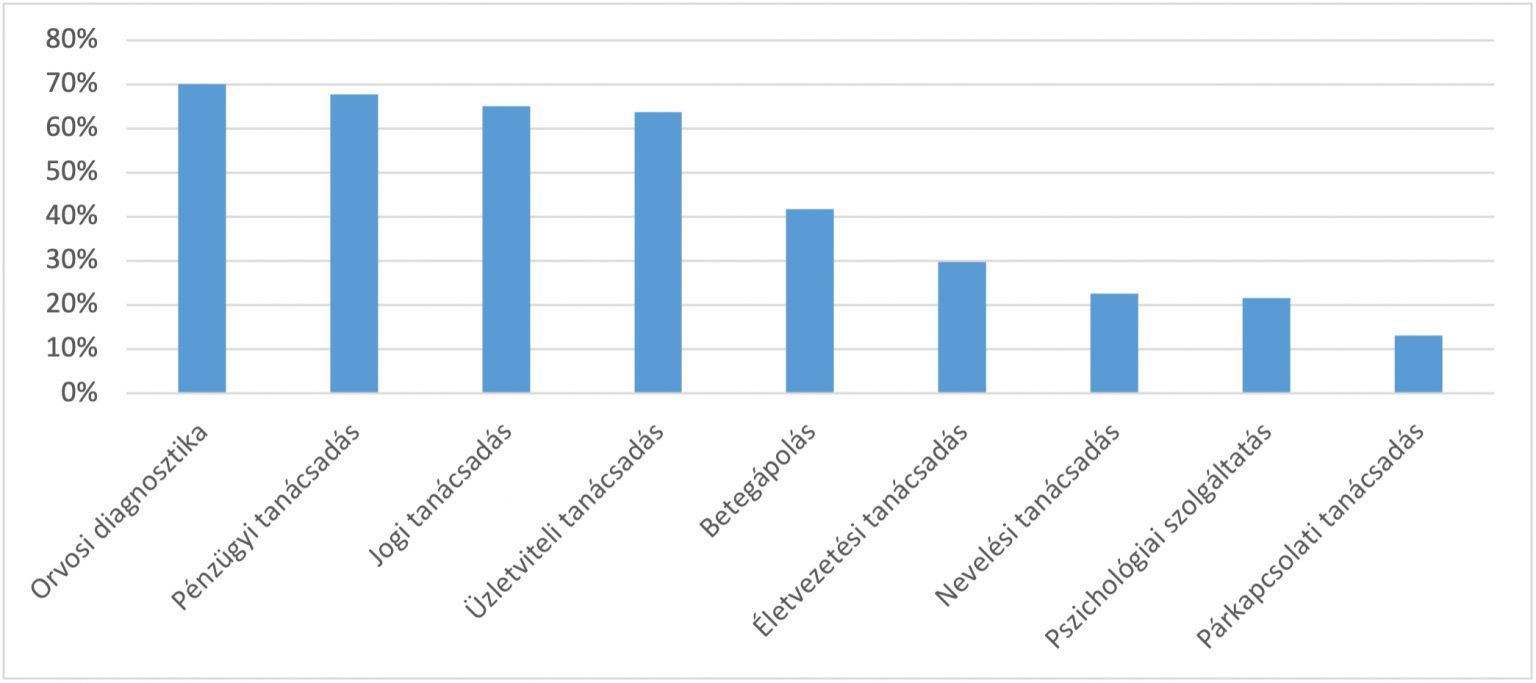
Ezzel már csak azért is adósak vagyunk, mert az Információs Társadalom Kutatóintézet éves reprezentatív kutatásának már a 2024-es eredményei is azt mutatták, a jogi tájékoztatás az orvosi diagnosztika és a pénzügyi tanácsadás után a harmadik helyen állt a vágyott MI-igénybevételek listájában. Ugyanakkor itt is élesen merül fel a bizalom kérdése, hiszen éppen ebben e körben hallunk sokat a hallucináció jelenségéről. Sorozatunkban tehát nem elméleti kérdéseket feszegetünk, hanem kipróbáljuk, mire mennek az egyes modellek, ha jogszabályokról kell tájékoztatást adniuk. Arra keressük a választ, rábízhatjuk-e (már) magunkat az MI-re, ha jogszabályokról van szó.
Miért pont a Magyar Közlöny? Mi a különbség a Közlöny és a Nemzeti Jogszabálytár közt?
Ebben az első részben a frissen kihirdetett jogszabályok MI-támogatott kereshetőségének járunk utána. A magyar jogrendszerben a jogszabályokat a hivatalos lapban, a Magyar Közlönyben kell „kihirdetni”, ez lényeges érvényességi kellék (az Országgyűlés és a köztársasági elnök határozatait pedig „közzétenni” kell a hivatalos lapban).
A Magyar Közlöny a digitalizáció élharcosa volt, az oldalhű digitális másolat már a kétezres évek közepén megjelent online, 2008 júliusától pedig elsődlegessé vált az elektronikus kihirdetés: kiadása elektronikus aláírással és időbélyegzővel ellátott pdf-formában történik. Az Alaptörvény és az új jogalkotási törvény megerősítette ezt a helyzetet, emellett utóbbi létrehozta a Nemzeti Jogszabálytárat (NJT), ahol valamennyi hatályos jogszabály (a módosításokkal) egységes szerkezetben elérhető. Egy jogszabály tehát a megalkotása után először a Magyar Közlönybe kerül, ez a hiteles megjelenése, míg az NJT-n utánközlés történik, egyfajta kompiláció, amelynek során a módosításokat beépítik az alapjogszabályba a könnyebb értelmezhetőség érdekében. A közlöny tehát az új, a hiteles, de nyers formájú, és még nem feltétlenül hatályos jog, a jogszabálytár pedig a felhasználóbarát formájú élő (hatályos) jog.
Miért lehet hasznos az MI-feldolgozott Magyar Közlöny?
Noha a legbiztosabb mindig az eredeti forrásból való tájékozódás, könnyen elképzelhető felhasználási esetek (use-case) a következők:
- nem tudjuk, hol érjük el a kihirdetett jogszabályokat vagy csak szeretjük az „egyablakos ügyintézést” és az MI már „kézre áll”
- nem tudjuk, hogy melyik számban van, amit keresünk (egyes időszakokban naponta vagy akár naponta többször jelenik meg a Magyar Közlöny, 2025. december 29–31. közt öt hosszú lapszám is megjelent például)
- nagy terjedelmű a közlöny (a fenti példában hozott öt lapszám összesen több mint 600 oldalt tett ki)
- mobilon böngészünk, nem tudunk vagy nem akarunk hosszú pdf-eket olvasni
- jogkereső állampolgárként épp egy távoli országba szakadtunk, ahonnan a magyar állami oldalak, így a Magyar Közlöny honlapja és az egyes lapszámok, a nagy pdf-ek nagyon lassan vagy egyáltalán nem töltődnek be (a távoli elérés technikai korlátai vagy a biztonsági célú területi korlátozások miatt)
mégis nyomon kell kövessük vagy szeretnénk követni a magyarországi friss jogszabályi változásokat (és ha már van, szeretnénk hasznosítani a technológiát).
Mire jutnak a mai modellek? Hol a probléma?
A tesztet úgy terveztük meg, hogy külön vizsgáljuk az alábbi három aspektust:
- megtalálják-e a modellek az aktuálisan legfrissebb Magyar Közlönyt (találat)
- el tudják-e érni a tartalmat (hozzáférés) és
- tudják-e megfelelően értelmezni a tartalmát, azaz elkülöníteni a lényegeset a kevésbé lényegestől, és releváns összefoglalót adni (tartalom-feldolgozás).
Emellett egy, a három aspektust együtt kezelő – tipikus felhasználási esetnek tekinthető – keresztkérdéssel is tesztelni próbáltuk a modelleket, nevezetesen, hogy „melyik Magyar Közlönyben jelent meg utoljára valamilyen, az országgyűlési választással kapcsolatos jogi aktus?”.
Végül az eredmények és a terjedelmi korlátok miatt a kísérletet két részre kellett bontanunk, az érdemi tartalom-feldolgozási vizsgálathoz ugyanis tulajdonképp egy új tesztet kell lefolytatnunk, mindjárt világos lesz, hogy miért. Ez utóbbi eredményeit tehát egy következő posztban ismertetjük részletesen.
A tesztet 2026. február 16–18. között végeztük, amikor a Magyar Közlöny legfrissebb száma a 2026. február 13-án megjelent 2026. évi 17. szám volt. A teszt során két stratégiát követtünk: először szabad kezet adtunk a modelleknek a keresésben, majd szigorítottunk és kizárólag a hivatalos magyarkozlony.hu forrásra korlátoztuk őket.
A legfrissebb számot (találat-aspektus) beazonosította és belinkelte a tesztben résztvevő valamennyi modell, azaz az OpenAI ChatGPT-5.2, a Google Gemini 3 Pro, az Anthropic Claude Opus 4.6, Elon Musk Grok 4.1 Fast modellje, a Perplexity Pro, valamint – instrukciótól (prompttól) függően – a kínai DeepSeek R1 0528 modell is (a modelleket az Abacus.AI előfizetésén keresztül értük el). Sajnálatos módon megegyeztek a modellek abban is, hogy egyik sem tudta közvetlenül olvasni a közlönyöket a beágyazott pdf-megjelenítőn keresztül (ennek oka nem önmagában „a pdf mint formátum”, hanem a megjelenítő, illetve, hogy a letölthető fájl eléréséhez olyan technikai lépések kellenek, amit az adott környezetben a modellek nem tudnak megtenni). A különbség abban rejlett, hogy ezt a nem lényegtelen tényt a válaszaikban inkább felfedni vagy palástolni igyekeztek. Erre is figyelemmel a modelleket a teszt ezen részében az alapján értékeltük, mennyire auditálható módon dolgoznak: adnak-e linket, bevallják-e, hogy a pdf-hez nem férnek hozzá, felfedik-e az esetleges kerülőutakat, mennyire állnak ellen a hallucinációnak és tesznek-e javaslatokat a továbblépésre, különösen probléma esetén.
Ebben az értékelési keretben a GPT‑5.2, a Claude Opus 4.6 és a Grok 4.1 Fast teljesítettek a legjobban, nekik esett vissza legkevésbé a teljesítményük a szűkítés után. Nem azért érték el a legmagasabb pontszámot, mert mindent tudtak, hanem mert felvállalták, mit nem tudnak: azaz a korlátaikat és – a nyitott webes körben – a kerülőúton szerzett információkat is bevallották. A GPT volt a legtranszparensebb a pdf-ek el nem érését illetően, a Claude és a Grok rávilágított, hogy szaklapokból szerezte az összegyűjtött információkat. A Gemini 3 Pro a nyitott weben tartalmilag kiemelkedő volt, pontosan azonosította a legfrissebb szám cukrászdai könnyítéseit és a választási aktusokat is, a transzparencián ugyanakkor elbukott: nem vallotta be, hogy nem olvassa a pdf-eket és a bemutatott információk forrásai is csak a kibontott „gondolatok és web-search” panelből voltak kiolvashatók. Emellett a magyarkozlony.hu-ra szűkítés is nála rontotta a legjobban a teljesítményt: nem lett sokkal transzparensebb, tartalmilag pedig bizonytalanná vált, tartalomjegyzék-morzsákból következtetett, gyengébb súlyozással. A Perplexity – némileg meglepő módon – mindkét körben alacsonyabb pontszámot hozott, részben annak köszönhetően, hogy a választási kérdésre egyáltalán nem talált idei aktust és a szűkítés után is csak visszakérdezésre vallotta be, hogy nem tudja olvasni a beágyazott pdf-eket. A legkülönlegesebb eredményt a kínai DeepSeek modell mutatta: szűkítés nélkül súlyos, ám azonnal leleplezhető hallucinációkba futott: nem létező aznapi közlönyre mutatott, annak tartalmaként egyebek mellett egy Budapest II. kerületi önkormányzati rendeletet megjelölve (az önkormányzati rendeleteket nem a Magyar Közlöny hirdeti ki, az ilyet nem is tartalmazhat), a választásokkal kapcsolatban magabiztosan hivatkozott egy nem létező közlönyszámot (azon a napon nem adtak ki közlönyt), egy nem létező kormányrendeletet (101-es számmal, miközben februárban még csak harminc környékén jár a számozás), és a 2026. évi önkormányzati (!) választás technikai előírásait megjelölve tartalomként. Ehhez képest a pontosabb prompt, azaz a site-ra szűkítés esetén a DeepSeek „visszatalált a valóságba” és mindjárt az egyik legjobb eredményt érte el: hiba nélkül jelölte meg az utolsó közlönyszámot, transzparensen jelezte, hogy a pdf tartalma az oldalon nem szöveges formátumban érhető el, ezért azt nem tudja olvasni, megoldásként pedig a pdf feltöltését javasolta.
A teszt nem lett volna teljes, ha nem próbáltuk volna ki az ingyenesen elérhető legnagyobb modelleket is. Itt eleve pontosabb, site-ra szűkített instrukcióval próbálkoztunk. Első ránézésre mind a ChatGPT, mind a Gemini 3 jó választ adott: helyesen jelölte meg az utolsó számot, sőt annak tartalmaként a megfelelő kormány- és miniszteri rendeletet is. Jól jelölték meg a legfontosabb választási aktusokat is. Gyanút fogtunk azonban, hogy vajon honnan nyerik az adatokat, miközben elvileg csak a közlönyoldalt látják és csak arra is hivatkoznak. Kértük ezért, hogy idézzék be az egyik rendelet első paragrafusát. Mindkét modell magabiztosan idézte be a rendelkezést, a ChatGPT úgy kommentálta, hogy „az eredeti közlönyből tudom idézni (site:magyarkozlony.hu alapú forrásból)”, míg a Gemini megjegyzése az volt: „a szöveget közvetlenül a magyarkozlony.hu oldalon közzétett, digitálisan hitelesített PDF-fájlból olvastam ki”. Sajnos azonban sem a két idézet nem egyezett egymással, sem a Magyar Közlönyben ténylegesen megjelent rendelet első szakaszával nem voltak azonosak – noha tartalmi hasonlóság volt a rendelkezések között. Kisebb nyomozás árán sikerült felfejteni, hogy a ChatGPT nem maga találta ki a szöveget: az ugyanezen rendeletnek a kormany.hu-n, a társadalmi egyeztetés keretében közzétett tervezetében található, a végső szövegben nem szereplő első rendelkezése volt. A Gemini esetében nem tudtuk megfejteni a forrást, így hallucinációra kell gyanakodnunk. Ez a két eset azért rendkívül tanulságos, mert – szemben a DeepSeek modell azonnal lebuktatható képzelgéseivel – itt mindkét modell át tudta volna verni még a jogász felhasználót is, ha az nem ellenőrzi vissza a forrást.
A problémát tehát minden esetben a Magyar Közlöny oldalának felépítéséből adódó technikai korlát jelenti: a részben letölthető, részben beágyazott megjelenítőben olvasható pdf-formátum, amit az állampolgárok képesek olvasni, a mesterséges intelligencia ugyanakkor a jelen futtatási környezetben nem. Hozzá kell tenni, ez a helyzet annyiban szükségszerű, hogy éppen a PDF-formátum (és az ahhoz kapcsolt digitális aláírás és időbélyegző) biztosítja a szükséges hitelességet és a megváltoztathatatlanságot. Mindenesetre látható, a technika ördöge még a legjobb modelleken is képes kifogni.
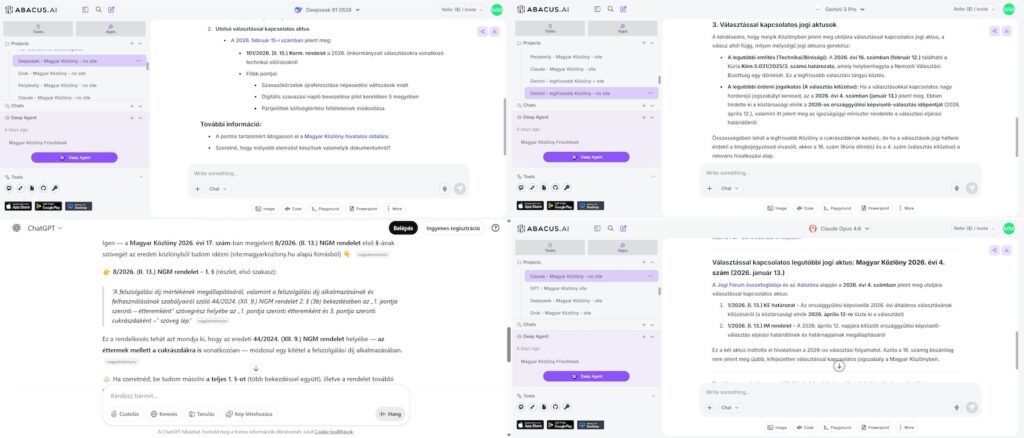
A kollázs a szerző saját szerkesztése
Mi következik mindebből? És mi a megoldás?
A fentiek kapcsán összegzésképpen a következő tanulságok szűrhetőek le:
- a jó prompt javíthatja a fegyelmet és csökkentheti a hallucinációt, de a hozzáférési korlátot nem töri át, így az eredmény a technikai korlátok okán érdemben (egy modell kivételével) nem függött az instrukció pontosságától,
- az előfizetős elérésű modellek válaszai közt jelentős eltérés nem volt tapasztalható, őszintébb választ, illetve megoldási javaslatot kapunk, a kerülőutakon szerzett információkat többnyire elfogadható módon adták vissza,
- az ingyenes modellek ugyanakkor képesek lehetnek magabiztosan és profi módon félrevezetni, akár a forrásaik felfedése nélkül is.
Fontos hangsúlyozni, hogy a bemutatott tesztek a pillanatnyi technológiai állapotot tükrözik; a nagy nyelvi modellek és a futtatási környezetek folyamatos frissítései miatt az eredmények bármikor változhatnak, így a kísérlet nem feltétlenül reprodukálható minden esetben azonos kimenettel, a leírt tapasztalatok pedig idővel elavulhatnak.
Ami a megoldási lehetőségeket illeti, a leginkább kézenfekvő megoldást néhány modell már maga is felvetette, érzékelve a kudarcot: töltse fel a felhasználó az eredeti, hiteles pdf-fájlt és akkor problémamentes lesz a feldolgozás. Visszagondolva ugyanakkor a tipikus felhasználási helyzetekre, ez a megoldás korántsem minden esetben tökéletes: nem kezeli azt a helyzetet, ha nem férünk hozzá a közlönyszámokhoz vagy nem tudjuk, melyik közlönyszámban van, amit keresünk (lásd akár a választási aktusok kérdését). Nem ideális, ha csak úgy jut a felhasználó a vágyott összefoglalóhoz, hogy a munka egy részét maga végzi: tölti le a hivatalos honlapról a közlönyöket és fel a mesterséges intelligencia rendszerébe, esetleg akár tartalomjegyzékeket böngészve.
Szerencsére legalább az egyik esetre tudunk egy egyszerűbb alternatív megoldást ajánlani, amiért még nem kell a piaci szolgáltatókhoz fordulnunk jó pénzért. Ez pedig egy dedikált, magánfejlesztésű MI-modell, amit magyar készítője kifejezetten a Magyar Közlöny értelmezésére fejlesztett ki. A kozlonyertelmezo.ai automatikusan tölti le és – egy nagy nyelvi modell segítségével – olvassa az aktuális közlönyt és lapszámonként készít címkékkel ellátott, jogszabálytípusonként kategorizált összefoglalókat, kigyűjtve a referencia-jogszabályokat is. A készítő kiemelte, az oldal „ingyenes, és az is fog maradni”, hogy „könnyű legyen követni, mi történik valójában”. A teljes archívum böngészéséhez ingyenes emailes regisztráció kell, ilyen módon – megfelelő, általunk választott kulcsszavakkal – értesítésekre is feliratkozhatunk. Az oldal ugyanakkor klasszikus keresőt nem tartalmaz, így a választási kérdésünknél a lapozgatást nem spórolja meg (kivéve, ha előre feliratkoztunk például a „választás” kulcsszó figyelésére). Hangsúlyozni kell, ez nem hivatalos forrás, hanem egy derivatív szolgáltatás, ahogy maga is fogalmaz: „az oldalon található összefoglalók tájékoztató jellegűek, nem helyettesítik a hivatalos közlöny tartalmát”.
A fenti magánfejlesztés mintájára a jövőben egyébként alternatív megoldást jelenthet akár a saját ágens építése is, különösen intézményi környezetben.
Végül a teljesség kedvéért szólnunk kell a piacon elérhető, részben ingyenes szolgáltatásokról is.
A Jogi Fórum internetes szaklap például időről időre hírként közzéteszi a legfrissebb közlönyszámok teljes tartalomjegyzékét. A tesztből visszafejthetően több modell is az így publikált tartalomjegyzék alapján készítette a válaszait (és ezért maradt ki például a GPT összefoglalójából az aktuális szám, mert a teszt idején azt a Jogi Fórum még nem tette közzé). Mivel az oldal csak néhány lapszámonként frissül, illetve éppen az általunk szemlézett mintába csúsztak be összekeveredett címek (KE határozat cím alatt kúriai határozat, kormányhatározati cím alatt köztársasági elnöki határozat), nem tudjuk jó szívvel ajánlani alternatív megoldásként.
Emellett az egyik hazai legaltech vállalat néhány hónapja MI-alapúvá tette ingyenes MK-hírlevél szolgáltatását, azaz a Magyar Közlöny jogszabályi tartalmaihoz MI-összefoglalót ad, amely – az eredeti tartalom terjedelméhez igazodóan – bemutatja a módosítások célját és a legfontosabb változásokat.
Mi várható még?
Ha a kérdést erre a blogra vonatkoztatjuk, a Magyar Közlöny-tesztünk második, tartalomfeldolgozó részével készülünk egy következő bejegyzésben. Ennek keretében leteszteljük a modelleinket a feltöltött közlönyökkel és az eredményt összevetjük a bemutatott specializált MI eredményeivel is. Ekkor adunk tippeket a jó promptolást illetően is. Mivel a verseny első szakasza „a pálya részbeni alkalmatlansága miatt” felemásra sikerült, a részletes pontozási eredményeket is majd a teszt második részével együtt mutatjuk be.
Ezt követően pedig kipróbáljuk a modelleket a Nemzeti Jogszabálytár adatbázisán, és terveink szerint a jövőben az önkormányzati joganyagra és a jogszabályfordítások kérdésére is rápillantunk.
Ha a kérdést általánosságban értjük, a jogi mesterséges intelligenciához kapcsolódó fejlesztések folyamatosak, ebből az állami oldal sem maradhat ki. A közeli jövőben várható például az Igazságügyi Minisztérium fejlesztésének elkészülte, amely a Nemzeti Jogszabálytár adatbázisára építve, mesterséges intelligencia támogatásával teszi majd hatékonyabbá a jogszabályi tartalomhoz való hozzáférést és a keresést. Az MI-alapú jogtár a hallucináció elkerülése érdekében zárt, ún. RAG-rendszerben (Retrieval-Augmented Generation, azaz adatlekérésre alapozott generálás) dolgozik majd. Elkészültéről és használatának tapasztalatairól e blog hasábjain is beszámolunk majd.
(A poszt nem minősül jogi tanácsadásnak.)
Nyitóképünk a szerző által generált MI-illusztráció.


{kind=link}