





A bejegyzés első része itt, harmadik része itt olvasható.
A multimodális szentimentelemzés egyre népszerűbb kutatási terület, melynek középpontjában a szövegalapú szentimentelemzés generalizálása áll olyan videókban, ahol a három kommunikációs modalitás egyszerre van jelen: nyelvi (beszélt szavak), vizuális (gesztusok) és akusztikus (hang).
A fő kihívás a multimodális szentimentelemzésben modalitásközi dinamika modellezése: a nyelvi, a vizuális és az akusztikus viselkedés kölcsönhatásainak értelmezése, amelyek változtatják a kifejezett érzelmek érzékelését, amit az 1. ábra szemléltet:
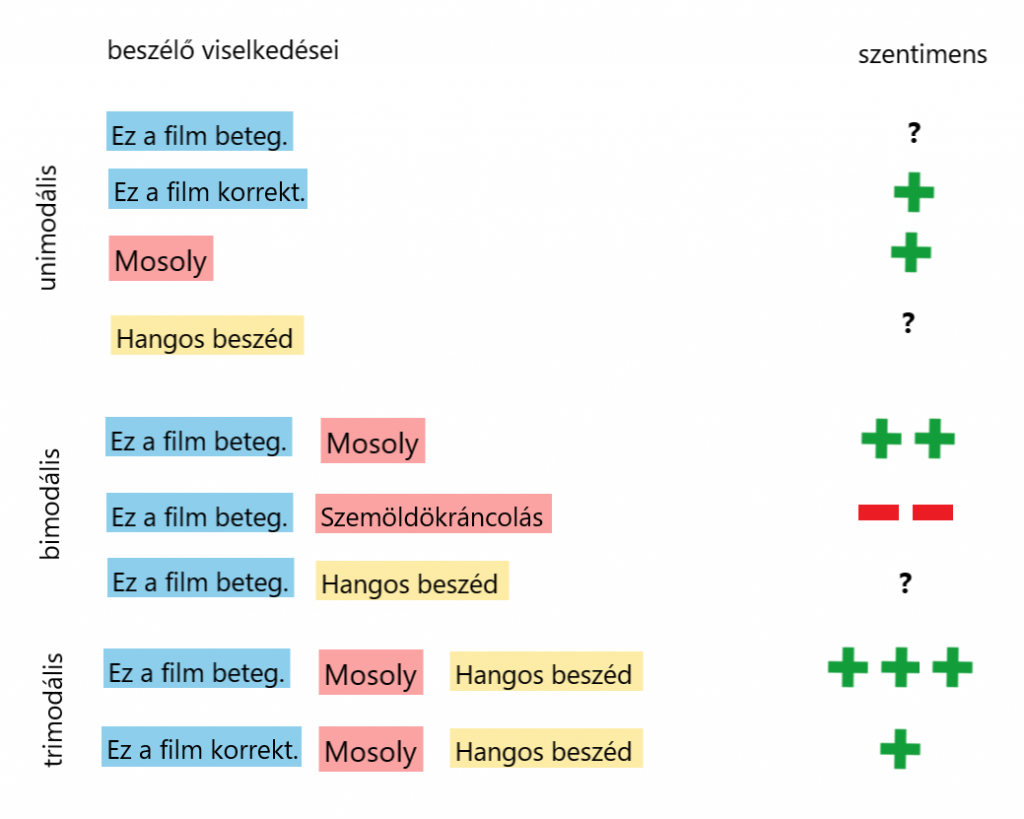
Az „Ez a film beteg.” kijelentés lehet önmagában kétértelmű, pozitív vagy negatív, de ha a beszélő mosolyog is hozzá, akkor pozitívnak fogjuk értékelni. Másrészt ugyanezt a kijelentést, ha szemöldökét ráncolva mondaná valaki, akkor negatívnak érzékelnénk. Az „Ez a film beteg.” még mindig kétértelmű lenne, hiába mondaná a beszélő emelt hangerővel. Ezek a példák a bimodális interakciókat szemléltetik. Példa a trimodális kölcsönhatásra, amikor a hangos beszéd növeli az érzelmeket erősen pozitívvá. Az intermodalitás összetett dinamikája a második trimodális példában látható, ahol az „Ez a film tisztességes.” kijelentés még mindig gyengén pozitív, a szó erős hatása miatt (a semleges vagy enyhén negatív felhang helyett).
A multimodális szentimentelemzés második kihívása az intramodális dinamikájának hatékony feltárása egy specifikus modalitásnál (unimodális interakció). Az intramodális dinamikák különösen nagy kihívást jelentenek a nyelvi elemzés számára, mivel a multimodális szentimentelemzést a beszélt nyelvnél vizsgáljuk. Egy olyan szóbeli vélemény, mint például: „Azt hiszem, rendben volt … Hmmm … hadd gondolkozzam … igen…nem… …oké, igen.” szinte soha nem fordul elő írott szövegben. A szóbeli véleményeknek az a változékony természete, ahol a megfelelő nyelvi szerkezetet gyakran figyelmen kívül hagyják, megnehezíti az szentimentelemzést. Vizuális és akusztikus modalitásoknak is megvan a maguk intramodális dinamikája, amely a térben és időben is kifejeződik. Gondoljunk itt a hangszín és az arcmimika, vagy a gesztikuláció változékonyságára.
Joggal merül fel a kérdés, hogy mire jó mindez? Több adat feldolgozása több erőforrást igényel és nagyobb komplexitást eredményez, illetve a hibalehetőségek számát is növeli. Bár mindez igaz, de a mérleg másik serpenyőjébe az kerül, hogy a multimodális megközelítés a hibaarány akár 10,5 százalékos csökkenését is eredményezheti ahhoz képest, mintha csak egy modalitást használnánk. Illetve lehetséges a hagyományos szövegelemzésen alapuló szótárakhoz képest, melyek csak szavakat tartalmaznak, úgynevezett multimodális szótárakat létrehozni. Ezekben a szavakon túl a gesztusok, illetve a vokális viselkedés elemei is megjelennek, így jobban teljesít szentimentintenzitás előrejelzés szempontjából. Az ezirányú kutatások segítenek jobban megérteni az emberi kommunikáció dinamikáját, mely számos alkalmazásban központi szerepet játszik, például az egészségügyben és az oktatásban.
A világ sok országában, így hazánkban is problémát okoz, hogy nincs elég tanár vagy a tanárok átlagéletkora már nagyon magas, és az utánpótlás hiányzik, illetve az oktatás színvonala nem elég magas, részben a túl magas osztálylétszámok miatt. A speciális igényű gyermekek számára a megfelelő tudással rendelkező tanárok száma sem elegendő. A váratlan helyzetek, mint például a Covid-19 járvány, extrém időjárási körülmények vagy egyéni élethelyzet miatt fennálló akadályoztatás is megoldhatók lennének az úgynevezett virtuális oktatási környezetek által.
Itt sok fejlett technológia, például a mesterséges intelligencia, a virtuális valóság, vagy a kiterjesztett valóság felhasználható. Mivel az oktatás a tanár–diák interakcióra épít, és a mesterséges intelligencia által vezérelt tanárok vagy tanársegédek számára fontos, hogy felismerjék a diákjaik érzelmi állapotát, így ezen interakciókat multimodális szentimentelemzésnek érdemes alávetni. Ez a diák számára is előnyös lenne, mert így a saját személyiségének legmegfelelőbb formában tud a „gépi” tanerő segíteni neki, illetve talán a gép–humán interakció kevésbé generál szégyenérzetet a diákban, mint egy hagyományos tanárnál. Egy másik pozitív vonatkozása az lenne egy ilyen rendszernek, hogy egyrészt a rendelkezésre álló erőforrások függvényében egy „gépi” tanár sokkal több diákkal tud egyszerre kapcsolatot teremteni, és ezáltal a tanulási folyamata is gyorsabb lesz, másrészt minden diák a saját képességeinek megfelelő tempóban tudja a tananyagot elsajátítani. Amennyiben megváltozna a tananyag, annak kidolgozása után sokkal gyorsabban kerülne be az oktatási rendszer véráramlatába.
Felhasznált irodalom
1. A. Zadeh, M. Chen, E. Cambria, S. Poria, és L.-P. Morency, „Tensor fusion network for multimodal sentiment analysis”, 2017, o. 1103–1114.
2. V. Pérez-Rosas, R. Mihalcea, és L.-P. Morency, „Utterance-level multimodal sentiment analysis”, 2013, köt. 1, o. 973–982.
3. A. Zadeh, R. Zellers, E. Pincus, és L.-P. Morency, „Multimodal sentiment intensity analysis in videos: Facial gestures and verbal messages”, IEEE Intelligent Systems, köt. 31, sz. 6, o. 82–88, 2016.
4. M. Soleymani, D. Garcia, B. Jou, B. Schuller, S.-F. Chang, és M. Pantic, „A survey of multimodal sentiment analysis”, Image and Vision Computing, köt. 65, o. 3–14, szept. 2017.
5. M. A. dos Santos Alencar, J. F. de Magalhães Netto, és F. de Morais, „A Sentiment Analysis Framework for Virtual Learning Environment”, Applied Artificial Intelligence, köt. 35, sz. 7, o. 520–536, jún. 2021.
„Az Innovációs és Technológiai Minisztérium ÚNKP-21-1-I-NKE-67 kódszámú Új Nemzeti Kiválóság Programjának a Nemzeti Kutatási, Fejlesztési és Innovációs Alapból finanszírozott szakmai támogatásával készült.”

