





A bejegyzés második része itt, harmadik része itt olvasható.
A szentimentelemzés (más néven vélemény bányászat vagy érzelmi mesterséges intelligencia) szisztematikusan azonosítja, kivonja, számszerűsíti és tanulmányozza az érzelmi állapotokat és szubjektív információkat a természetes nyelvfeldolgozás (natural language processing vagy leggyakrabban egyszerűen csak NLP), szövegelemzés, számítógépes nyelvészet és biometria segítségével.
Természetes nyelvfeldolgozás a nyelvészet, számítástechnika és mesterséges intelligencia egyik alterülete, ami a számítógép és az emberi nyelv interakcióival foglalkozik, konkrétan azzal, hogy hogyan lehet számítógépeket beprogramozni, hogy feldolgozzanak és elemezzenek nagy mennyiségű természetes nyelvi adatot. Célja, hogy a számítógép „megértse” a dokumentumok tartalmát, beleértve az adott nyelv kontextuális árnyalatait is. A 2010-es évekre beléptünk a neurális hálózatokon alapuló természetes nyelvfeldolgozás korába, illetve olyan szintre fejlődött a módszer, hogy a modellek 80 százalékot meghaladó hatékonysággal dolgoznak, ami azt jelenti, hogy utolérték az átlagos emberi teljesítményt. Természetesen ez nem azt jelenti, hogy a képessé váltak hibátlanul a „sorok között” olvasni, de reálisan nézve: az adott szöveget olvasó ember érzékenysége, kulturális háttere, műveltsége is meghatározza, hogy mennyire jutnak el hozzá a rejtett tartalmak. Ha feltételezzük, hogy lenne egy tökéletes algoritmus, ami hibátlan elemzésre képes, ez esetben is probléma lenne, hogy az emberek nagyjából az esetek 20 százalékában nem értenének egyet az algoritmus elemzésének eredményével (ahogy ezt egy másik emberrel sem tennék).
A biometria fogalma mely régebben biológiai statisztikát jelentett, újabban személyek egyedi (fizikai vagy viselkedésbeli) tulajdonságain alapuló azonosítását jelenti. A viselkedés vizsgálatára egy újabb tudományág, a behaviometria foglalkozik.
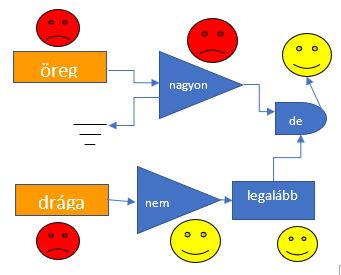
Valahogy így lehet elképzelni magát az szentimentelemzés folyamatát, ha egy hétköznapi mondatot nézünk, mint például „Az autó nagyon öreg, de legalább nem drága.” Vannak szavak, amik negatív jelentést hordoznak (öreg és drága), de ezek jelentése megfordulhat jelzők, illetve határozószavak által (nagyon, nem, legalább), illetve maga a nyelvtani szerkezet is árnyalhatja a mondatunk értelmét. Általában az érzelmek nagyságának megfelelően hozzárendelésre került egy pontszám minden szóhoz / kifejezéshez egy előre meghatározott skála alapján, ahol például -10 a legnegatívabb, és +10 a legpozitívabb érték, a 0 pedig a semlegest jelenti.
Végül a teljes tweetben, szövegben, hozzászólásban összesítésre kerül annak szentiment tartalma, és ez alapján csoportosításra kerül – általában egy hármas skálán: vannak semleges tartalmú üzenetek, illetve negatív és pozitív tartalmúak. Általánosságban elmondható, hogy a semleges üzenetek a 60–80%-át teszik ki az összes üzenetnek. Ennek az egyik oka lehet, hogy az üzeneten belüli szentimentek semlegesíthetik egymást, másrészt lehetséges, hogy az üzenet szentiment szempontból nem tartalmaz olyan szavakat, melyeket relevánsak lennének (érzelmi töltés alapján).
A szentimentelemzés sok területen felhasználják, ráadásul folyamatosan bővülő körben, így a teljesség igénye nélkül csak néhány területet megemlítve:
- üzleti információszerzés: általában a vállalatok érdeklődésének ez a terület áll a fókuszában. Mivel a marketingköltségek a vállalati költségvetésben nagyobb tételeket szoktak jelenteni, így érthető módon érdekeltek a nagyközönség véleményének megismerésében, elemzésében és várható véleményének előrejelzésében saját márkáik és termékeik vonatkozásában. Vagy a konkurencia termékeiről szóló vélemények elemzésében, egyfajta piaci pillanatfelvétel kialakításában. Az ezen tevékenységek automatizálása, illetve automatizált tömör és összegző jellegű jelentések készítése a kutatás és fejlesztés egyik legnagyobb aktivitású területe;
- termékfejlesztés: egy adott terméknek milyen funkciójával vagy részével nagyon elégedettek a vásárlók, és mi az, amit gyengébbnek tartanak, mi az, ami megítélésük szerint hiányzik a termékből;
- a feljebb bemutatott rendszerek fejlesztése állami hírszerzési felhasználásra, például az ellenfél kommunikációjának megfigyelése, információs műveletek hatékonyságának értékelése, illetve ellentevékenységek tervezése, monitorozása;
- online befektetési fórumok szentimentelemzése: a befektetők egy adott részvény, üzlet, részvényindex vonatkozásában milyen véleményen vannak, illetve ez alapján milyen tőzsdei árfolyamváltozás várható;
- korai poszttraumás stressz szindróma (ismertebb angol rövidítéssel: PTSD) kialakulásának figyelmeztető jeleinek előrejelzése: a pszichológusok számára nyújthat segítséget, bár e betegség komplex jellege miatt nehezen kiértékelhető. Strukturált kérdőívek segítségével a szakértőket megközelítő pontossággal tudta az algoritmus megállapítani, hogy valaki a veszélyeztetett csoportba tartozik-e. A kutatás központja az Amerikai Egyesült Államok, mivel Irakban és Afganisztánban az elmúlt 20 évben közel 2 millió amerikai katona teljesített szolgálatot, és a becslések szerint a kiküldetésből hazatérő katonák 20-35 százaléka küzd PTSD-vel vagy súlyos depresszióval;
- a mesterséges intelligencia fejlesztése: egyik kulcsa az érzelmek kérdésköre e területnek, illetve mindazon kutatási területeknek, amik ebből eredeztethetők. A fő kérdés nem is az, hogy intelligens gépek tudhatnak-e érezni, hanem hogy a gépek lehetnek-e intelligensek érzelmek nélkül. E kérdés nem mentes némi filozófiai fennhangtól, továbbá a szakirodalomban sincs konszenzus. Az érzelmek nehezen megfogható entitások, így kategorizálásuk sem triviális. Több modell is született, melyek alapján a szakirodalomban az érzelmek elkülönítését végezni szokták szentimentelemzés során, általánosságban elmondható, hogy a felismert érzelmek minőségi és mennyiségi mutatói folyamatosan bővülnek.
Felhasznált irodalom
1. Cambria, E., Y. Li, F.Z. Xing, S. Poria, és K. Kwok. „SenticNet 6: Ensemble Application of Symbolic and Subsymbolic AI for Sentiment Analysis”, 105–14, 2020.
2. Erik Cambria, Dipankar Das, Antonio Feraco, és Sivaji Bandyopadhyay, szerk. A Practical Guide to Sentiment Analysis. 2017. kiad. Socio-Affective Computing. Cham, Switzerland: Springer
3. Susanto, Y., A.G. Livingstone, B.C. Ng, és E. Cambria. „The Hourglass Model Revisited”. IEEE Intelligent Systems35, sz. 5 (2020): 96–102.
4. Vadim Kagan, Edward Rossini, és Demetrios Sapounas. Sentiment Analysis for PTSD Signals. SpringerBriefs. Springer, 2013.
„Az Innovációs és Technológiai Minisztérium ÚNKP-21-1-I-NKE-67 kódszámú Új Nemzeti Kiválóság Programjának a Nemzeti Kutatási, Fejlesztési és Innovációs Alapból finanszírozott szakmai támogatásával készült.”

